
Despite our growing ignorance, we must decide

Note: This post on our inability to access the information we need to make big decisions is part of a chapter, "The madness of not knowing," in my upcoming book, Big Decisions: Why we make decisions that matter so poorly. How we can make them better.
My mother encouraged me to read and learn. But she cautioned me, “The more you learn the less you will know.” That was her way of saying that learning opens whole domains about which we were previously ignorant and shows us how much more there is to learn.
That thought leads to the necessary understanding that our decision making is dependent on knowledge we do not have and can never completely know.
An estimate by Google illustrates the impossible challenge of knowing everything: In 2010 Google estimated that 129,864,880 different books had been published since Gutenberg invented the printing press in 1440. An updated estimate suggests the number is even higher: 134,021,533 unique book titles as of 2015.[i]
356 millennia to read
One wag estimates that it would take a person 356,164.39 years to read every book ever written, not accounting for new books published after he or she started reading. The estimate is based on reading 12 hours a day and the average book taking 12 hours to read.[ii]
The share of what we don’t know is relentlessly increasing, as evidenced by a UNESCO estimate that 2,200,000 new book titles are now being published annually worldwide.[iii]
How can we be expected to keep up with this torrent when, on average, Americans only read 12 books a year and when more than a quarter of Americans don’t read any books at all?[iv]


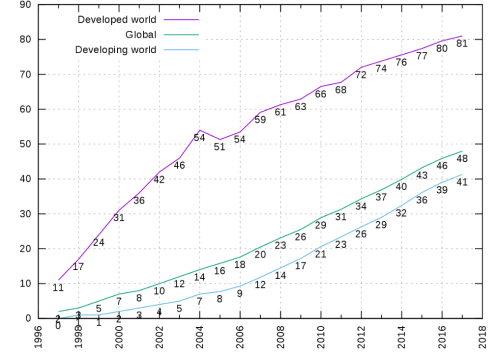
International Telecommunications Union
Those who do use the Internet are busily searching for information. Daily web searches on Google alone total 3.5 billion, which equates to 1.2 trillion Google searches per year worldwide.[vii]
And we are spending more and more time on our devices, around six hours a day in the U.S and even more in some countries, much of it seeking and consuming information.

World Bank
Too deep to know
Yet, our web searches are not scratching the surface of what’s posted on websites. The indexed World Wide Web contains at least 4.52 billion pages.[viii] This estimate does not include non-indexed pages and pages on the deep web which search engines will not pick up. There could be as many as 180 quadrillion web pages on the internet if both indexed and non-indexed, that is, surface and deep web pages, are counted. [ix]
If you think reading every book would be impossible (remember the estimate that it would take 356,164 years reading 12 hours a day?), the task of reading every web page would be 100 times more daunting. It would take you 23.8 million years, without any time for rest![x] (Of course, as already noted, we individually can’t even find or access the great bulk of the web.)
The impossibility of knowing all that we need to know for our big decisions is not just a matter of our ignorance of the existing body of human knowledge. It’s recognizing that what humanity collectively knows is expanding exponentially.
The explosive growth in scientific knowledge demonstrates the unbounded nature of knowledge and our ignorance, how little we really know. Columbia University biologist Stuart Firestein observed, “We should remember that when a sphere becomes bigger, the surface area grows. Thus, as the sphere of scientific knowledge increases, so does the surface area of the unknown.”[xi]
Explosive, accelerating growth
One indicator of the growth of knowledge is offered by the explosive growth in scientific papers and citations in these papers. A study of the number of papers cited between 1908 and 2012 and their age suggests that global scientific output is increasing 8% to 9% annually and, thus, scientific knowledge is doubling every nine years.[xii] And this growth has accelerated: The study looked at the rate at which science has grown in terms of number of publications and cited references since the mid-1600s. The researchers “identified three growth phases in the development of science, which each led to growth rates tripling in comparison with the previous phase: from less than 1% up to the middle of the 18th century, to 2 to 3% up to the period between the two world wars and 8 to 9% to 2012.”[xiii]
That means someone with who graduated from high school 18 years ago is faced with double the amount of scientific knowledge than their high school classes potentially considered.
The increase in scientific knowledge is mirrored by – or better said, enabled by – the relentless increase in data processing and storage capacity.
Gordon Moore, Intel’s founder, observed in 1965 that the power of computers – specifically, the number of transistors per square inch on a computer chip – roughly doubled every two years. This observation has stood the test of time as the 40-year chart of transistor count on chips shows.[xiv]

Chart by Anynobody, licensed under the Creative Commons Attribution-Share Alike 2.0 Generic license.
For example, Intel has been able to double chip density annually and can now pack more than 100 million transistors in each square millimeter of chip (10 nm chip density).[xv] One observer notes, “from the introduction of the 22 nm node in late 2011 to the ramp-up of Intel's 10 nm in 2018 we have observed close to 7x density increase over the span of 7 years.”[xvi]
This mushrooming computing capability is enabling us to create and store data at an exponential rate.
10 times more data
By 2025 the world will be creating ten times as much data as it is now, 163 zettabytes of data a year, according to research firm IDC. (One zettabyte is one trillion gigabytes!) Now our current data creation rate is 16.3ZB a year. But even with increased storage capacity, IDC predicts that of the total amount of data that will be generated between now and 2025, less than 1%, only 19ZB, will be stored.[xvii]
This tidal wave of so much data and knowledge that we never can know and access means that we as decision makers must make our big decisions without possessing all the existing knowledge that could make our decisions better. “Unknowability” is an unavoidable characteristic of real-world decision-making.
Endnotes
[i] http://mentalfloss.com/article/85305/how-many-books-have-ever-been-published
[ii] https://www.quora.com/How-long-would-it-take-to-read-every-book-ever-written
[iii] http://www.worldometers.info/books/
[iv] http://www.pewinternet.org/2016/09/01/book-reading-2016/
[v] "Individuals using the Internet 2005 to 2014", Key ICT indicators for developed and developing countries and the world (totals and penetration rates), International Telecommunication Union (ITU). https://www.itu.int/en/ITU-D/Statistics/Documents/facts/ICTFactsFigures2017.pdf
[vi] https://www.internetworldstats.com/emarketing.htm
[vii] https://www.smartinsights.com/search-engine-marketing/search-engine-statistics/
[viii] http://www.worldwidewebsize.com/
[ix] https://askwonder.com/q/how-many-web-pages-are-on-the-internet-presently-57336062ded4a34e0083c6b0
[x] https://www.quora.com/How-long-would-it-take-to-browse-the-entire-internet
[xi] Nature 484, 446–447 (26 April 2012)DOIdoi:10.1038/484446a Philosophy: What we don't know Nature Michael Shermer Ignorance: How it Drives Science Stuart Firestein Oxford University Press: 2012. 256 pp. 9780199828074 https://www.nature.com/articles/484446a
[xii] http://blogs.nature.com/news/2014/05/global-scientific-output-doubles-every-nine-years.html
[xiii] https://www.zbw-mediatalk.eu/wp-content/uploads/2017/07/1402.4578.pdf
[xiv] https://www.intel.com/content/www/us/en/history/museum-gordon-moore-law.html
[xv] https://spectrum.ieee.org/nanoclast/semiconductors/processors/intel-now-packs-100-million-transistors-in-each-square-millimeter
[xvi]https://fuse.wikichip.org/news/525/iedm-2017-isscc-2018-intels-10nm-switching-to-cobalt-interconnects/
[xvii] https://www.forbes.com/sites/andrewcave/2017/04/13/what-will-we-do-when-the-worlds-data-hits-163-zettabytes-in-2025/#3c8e6f83349a